Microsoft SQL Failover-Cluster: Einführung
In diesen und den darauf folgenden Seiten möchte ich Schritt für Schritt das Planen und Konfigurieren eines Microsoft SQL Failover-Clusters erklären, sowie die Voraussetzungen für ein Shared Storage schaffen. Allerdings sollten wir zuerst die grundlegenden Begriffe klären. Was ist eigentlich ein Failover-Cluster und warum kann er sinnvoll sein? Schaut man sich die Microsoft Produktpalette an, lassen sich bereits in sehr vielen unterschiedlichen Bereiche ein Failover-Cluster aufbauen. Sei es für DHCP, ein Fileserver oder auch eine Hyper-V Virtualisierungsumgebung – all diese Dinge können mit einem Cluster hoch verfügbar gestaltet werden.
Ein Failover-Cluster ist dabei nichts anderes als ein Verbund aus unabhängigen Server, die gemeinsam die Verfügbarkeit und auch Skalierbarkeit eines Services oder Applikation erhöhen. Fällt im Fehlerfall ein Node einer Gruppe aus oder muss gewartet werden, können die restlichen Nodes den Betrieb aufrecht erhalten. Ein Cluster besteht dabei mindestens aus 2 Server und aus einem darunterliegenden, gemeinsamen Storage.
Inhaltsverzeichnis
- Microsoft SQL Failover-Cluster: Einführung
- Microsoft SQL Failover-Cluster: iSCSI Server
- Microsoft SQL Failover-Cluster: Cluster konfigurieren
- Microsoft SQL Failover-Cluster: SQL installieren
Weitere Tutorials zu dieser Reihe folgen noch!
Failover-Cluster planen
Ein Cluster muss dabei zwingend immer aus mindestens folgenden Komponenten bestehen:
- 2 Nodes: Sie übernehmen die eigentliche Applikation. In unserem Fall wird ein MSSQL Service darauf ausfgeführt.
- Shared Storage: Die Daten der Applikation werden nicht auf den Nodes selbst gespeichert. Im Fehlerfall muss der funktionierende Server den Betrieb in wenigen Sekunden übernehmen können, daher müssen die betriebswichtigen Daten auf einem Shared Storage gelagert werden. Dieser Storage kann entweder aus einem SAN (Storage Area Network) oder einem iSCSI Target/Initiator System (TCP/IP) bestehen. Im Optimalfall sind auch das Storage, sowie das Network redundant und ausfallsicher ausgelegt. Möchte man im Microsoft Umfeld bleiben, bietet sich S2D (Storage Space Direct) an, mit welchem man in wenigen Schritten ein hyper-konvergentes System aufbauen kann. Da das den Rahmen sprengen würde, bleiben wir bei einem einfachen Storage, ohne Redundanz.
- Network: Zumindest ein Cluster- sowie ein Storagenetzwerk werden benötigt. Optional lässt sich der Heartbeat auch noch auf eine eigene NIC (Network Interface Card) legen.
Der Aufbau für dieses Tutorial sieht wie folgt aus:
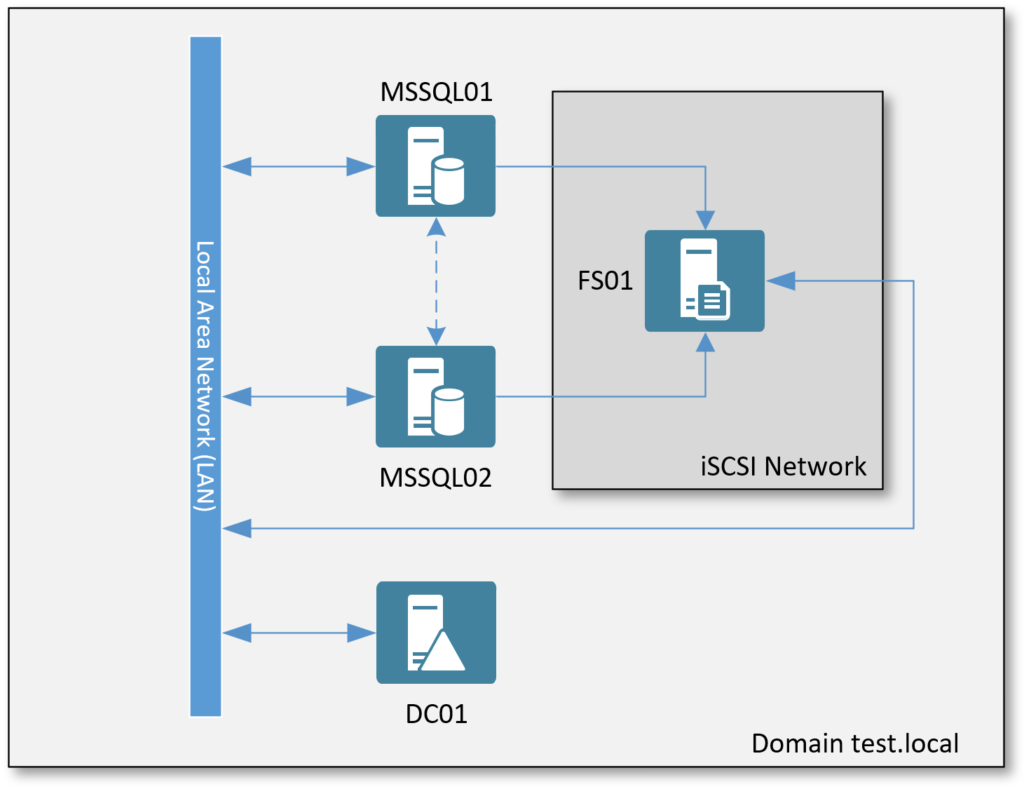
- DC01: Alle Server sind der Domäne „test.local“ gejoined und verfügen somit über eine Anbindung zum AD.
- MSSQL01/02: Diese beiden Server bilden den Hauptbestandteil des Failover-Clusters.
- FS01: Dabei handelt es sich um einen einzelnen Windows-Server, welche iSCSI LUNs als Shared Storage für den Cluster zur Verfügung stellt.
- iSCSI Network: Dieses Netzwerk ist ausschließlich zur Kommunikation zwischen Cluster und iSCSI LUNs gedacht.
Der gesamte Aufbau wird über einen Hyper-V Host durchgeführt. In einer produktiven Umgebung sollte zum Schutze der Ausfallsicherheit zumindest ein zweiter, physischer Host eingeplant werden. Außerdem müssen mindestens zwei Netzwerkkarten, sowie ein redundantes Netzwerk vorhanden sein.
Im weiteren spreche ich außerdem hauptsächlich von VMs (Virtual Machines). Der Aufbau kann natürlich auch auf physischen Hosts durchgeführt werden.
Die Cluster Quorum Disk
Das Wort Quorum kommt eigentlich aus der Politik. Darunter versteht man die Anzahl jener Stimmen, die benötigt werden, damit eine Abstimmung an Gültigkeit erlangt. Doch wie passt das zu einem Failover Cluster? Man stelle sich folgendes Szenario vor: Wir betreiben einen Cluster mit zwei Nodes. Solange die beiden Knoten miteinander sprechen können, gibt es kein Problem. Doch was passiert in dem Fall, wenn beide Knoten sich unter einander nicht mehr pingen können, den Shared Storage jedoch erreichen? Beide Server würden in diesem Fall versuchen die Cluster Ressourcen online zu nehmen, da sie davon ausgehen, dass der Partner offline ist. Beide Knoten probieren also immer wieder den MSSQL Service zu starten und die SQL iSCSI Disk zu mounten – das würde nicht gut enden. Daher hat Microsoft die Mehrheitsentscheidung eingeführt. Das bedeutet, dass ein Cluster nur wieder online gehen darf, wenn mindestens 50% der Teilnehmer verfügbar sind. Da das bei einem Cluster mit einer geraden Anzahl an Teilnehmern nur schwer funktioniert, wurde die Quroum Disk geschaffen. Jener Node, der diese Disk mounten kann, darf die Services online nehmen. Eine ausführlichere Beschreibung zur Funktionsweise gibt es übrigens direkt von Microsoft. Darin werden auch Beispiele mit mehr als 2 Server beschrieben (das sieht etwas anders aus): Understanding cluster and pool quorum
IP-Adressen eines Failover-Clusters
Zur Planung gehört ebenfalls die Vergabe der IP-Adressen. Bei einem Microsoft SQL Failover Cluster werden insgesamt 4 IP-Adressen benötigt. Diese teilen sich wie folgt auf:
- 2 IPs: Cluster Nodes
- 1 IP: Cluster IP-Adresse – darunter ist der Cluster Service an sich erreichbar
- 1 IP: MSSQL IP-Adresse – darunter sind die MSSQL Instanz, sowie die darauf liegenden Datenbanken erreichbar
Vorbereitung
Da ich in diesem Tutorial hauptsächlich auf die Komponenten eines Microsoft Failover-Clusters eingehen möchte, wird ein funktionierendes Netzwerk, Active-Directory und drei „leere“ VMs für die Cluster-Nodes, sowie den Fileserver vorausgesetzt. Der Testaufbau basiert auf der Version Windows Server 2019, kann aber auch problemlos mit 2016, sowie 2012 nachgebaut werden.
Netzwerkkonfiguration:
- Local Area Network: VLAN50 – 10.0.50.0/24 (10.0.50.254 Default Gateway)
- iSCS Network: VLAN51 – 10.0.51.0/24 (10.0.51.254 Default Gateway)
Weiter geht es mit der Konfiguration des iSCSI-Servers, damit wir die Grundlage – das gemeinsame Storage – schaffen können: Microsoft SQL Failover-Cluster: iSCSI Server


Hallo
Erstmals vielen Dank für diese Tutorial! Sehr toll gemacht. Eine Frage bezüglich dem Clustering. Wenn ein WSFC bereits existiert und ein Cluster ebenfalls (Hyper-V), kann über über WSFC ein neuer Cluster erstellt werden für den SQL-Cluster?
Besten Dank!
Hallo,
dem Lob schließe ich mich gerne an und greife auch gleich die Frage von jeff auf.
Lässt sich ein SQL Failovercluster auch erstellen, wenn ein SQL Server bereits besteht? Oder sollte/muss alles frisch installiert werden?
Viele Grüße
Grüß dich,
ja – zu einem bereits deployten Single Node MSSQL Server kann man relativ problemlos einen weiteren Node hinzufügen. Im Grunde geht das sogar ohne Downtime (in den meisten Fällen), man sollte aber sicherheitshalber trotzdem ein Wartungsfenster einplanen.