Microsoft SQL Failover-Cluster: SQL installieren
Mit dieser Tutorialreihe möchte ich Schritt für Schritt einen Microsoft SQL Failover-Cluster aus dem Boden stampfen. Du befindest dich dabei beim vierten Artikel zu dieser Reihe, falls du die letzten Parts noch nicht gelesen hast, würde ich dir folgenden Post ans Herz legen: Microsoft SQL Failover-Cluster: Einführung. Dort erfährst du das grundlegende Konzept des Clusters, sowie eine Anleitung, wie man iSCSI LUNs auf einem Windows Server bereitstellt. Im vierten und letzten Teil möchte ich mich auch die Installation der beiden MSSQL Instanzen konzentrieren.
Vorbereitung
- zwei SQL-Windows Server in der AD-Domäne + korrekter Netzwerkkonfiguration – siehe Microsoft SQL Failover-Cluster: Einführung
- iSCSI LUNs – siehe Microsoft SQL Failover-Cluster: iSCSI Server
- Failover Cluster aufsetzen und anpassen – siehe Microsoft SQL Failover-Cluster: Cluster konfigurieren
MSSQL-Instanz installieren
Der MSSQL Server Agent, sowie die Database Engine sollten unter einem eigenen AD-User laufen. In meinem Fall trägt dieser den Namen „svc.mssql01“ und ist auf beiden Cluster-Nodes in der lokalen Administratorengruppe (kein Domain Admin!).
 Schritt 1: AD-User „svc.mssql01“ anlegen |
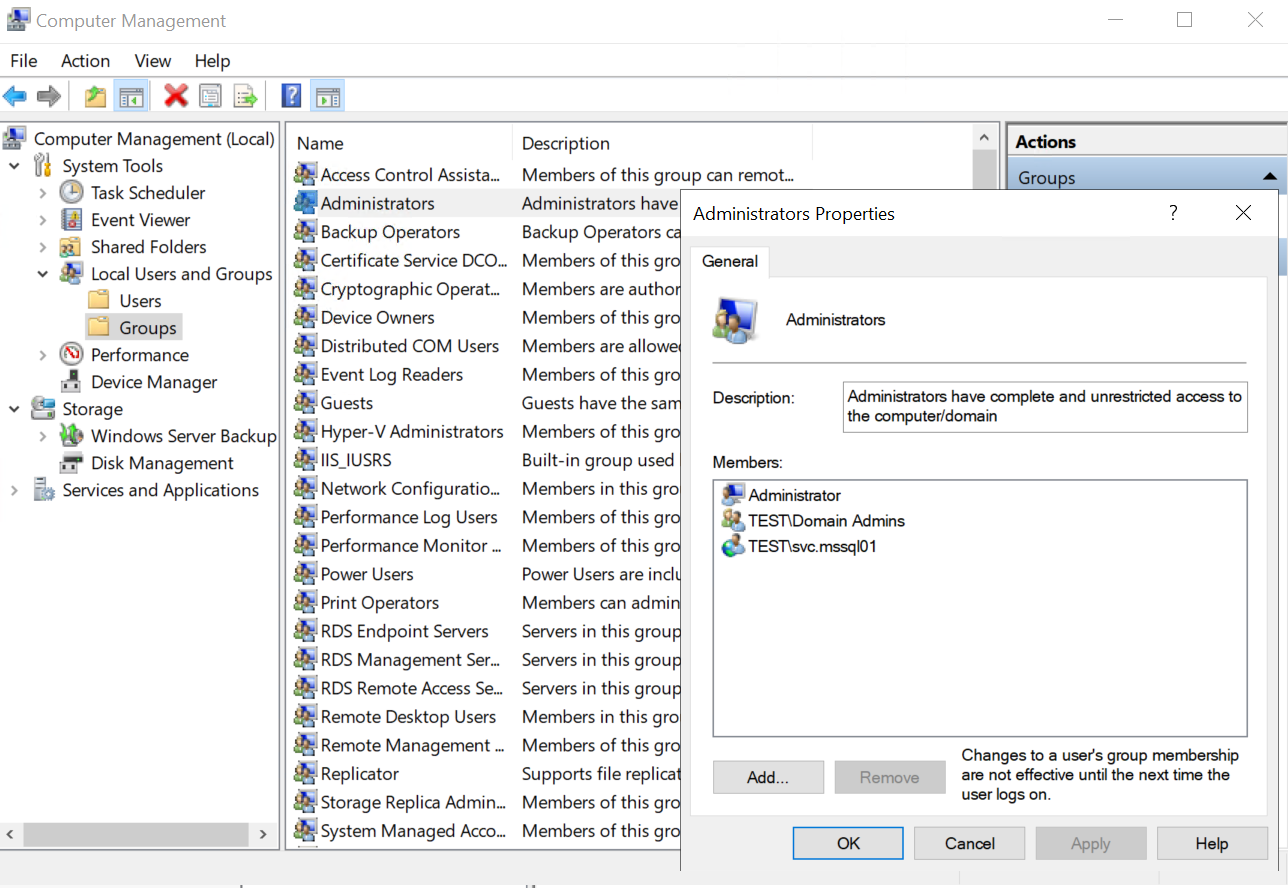 Schritt 2: svc.mssql01 auf den Nodes als lokaler Administrator hinzufügen |
Anschließend können wir mit der Installation der MSSQL-Instanz fortfahren. Die nachfolgenden Schritte müssen auf jenem Node zuerst ausgeführt werden, der momentan die Cluster Disks inne hat.
 Schritt 1: New SQL Failover Cluster Installation |
 Schritt 2: Instanz Check erfolgreich abgeschlossen |
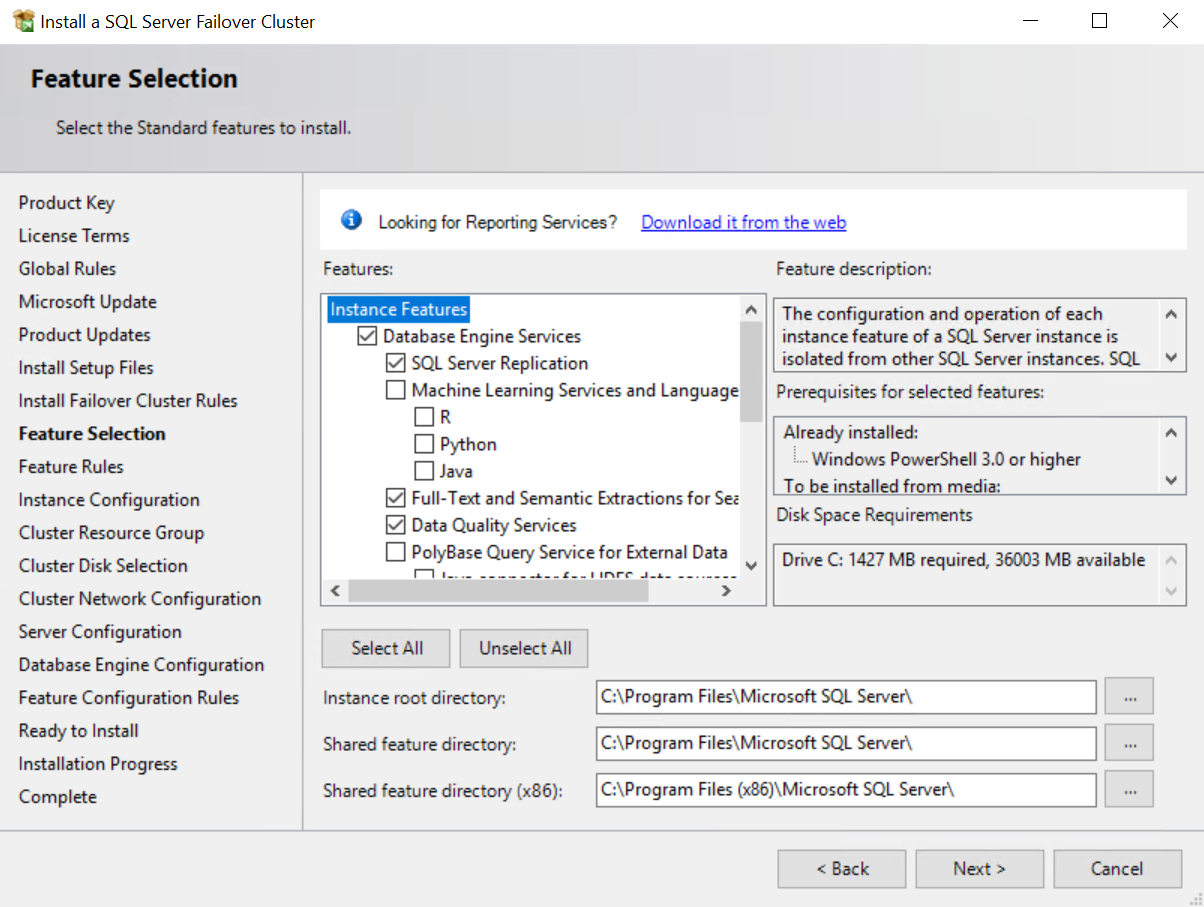 Schritt 3: Features auswählen und installieren |
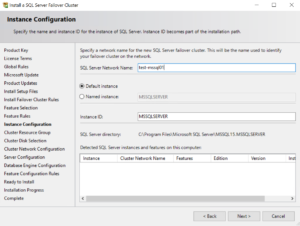 Schritt 4: Netwerknamen des Clusters festlegen |
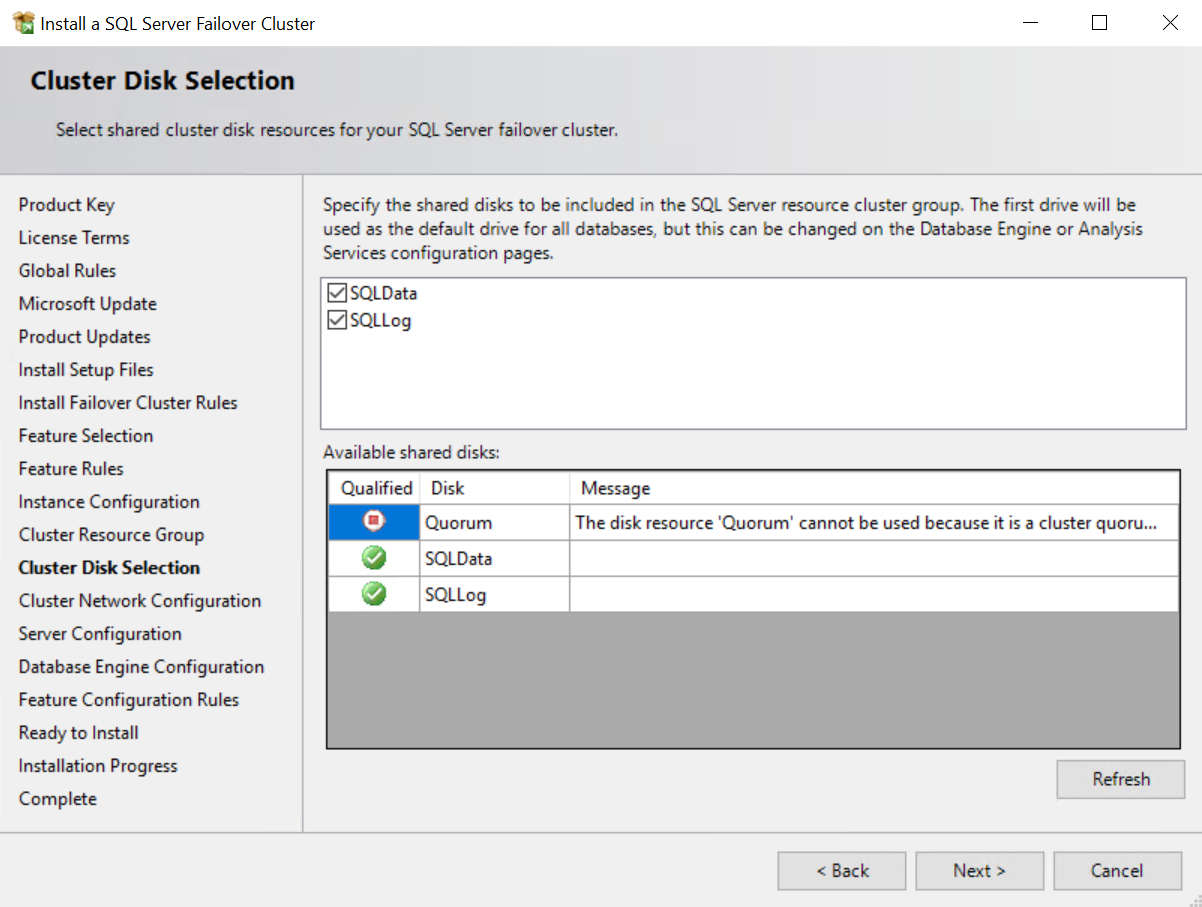 Schritt 5: Cluster Disks hinzufügen |
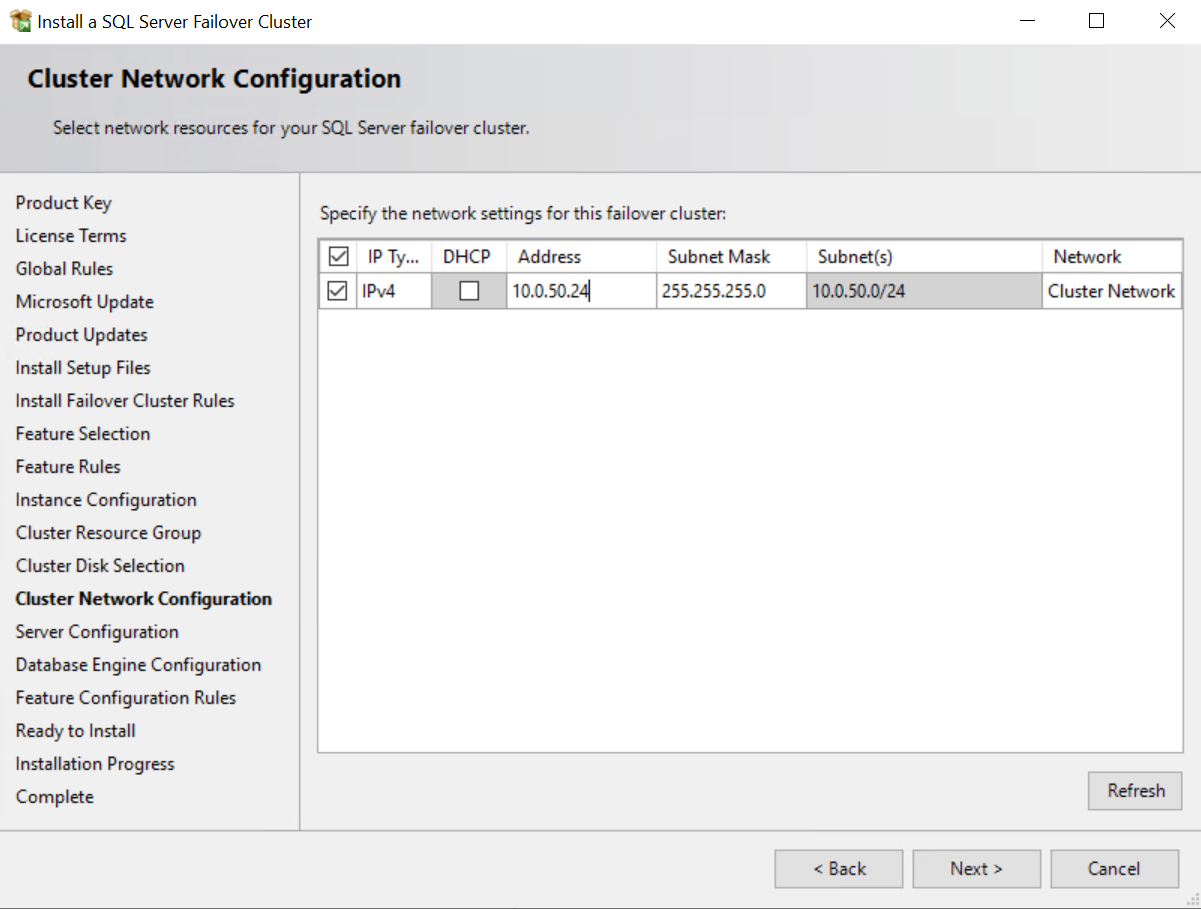 Schritt 6: Netzwerk konfigurieren |
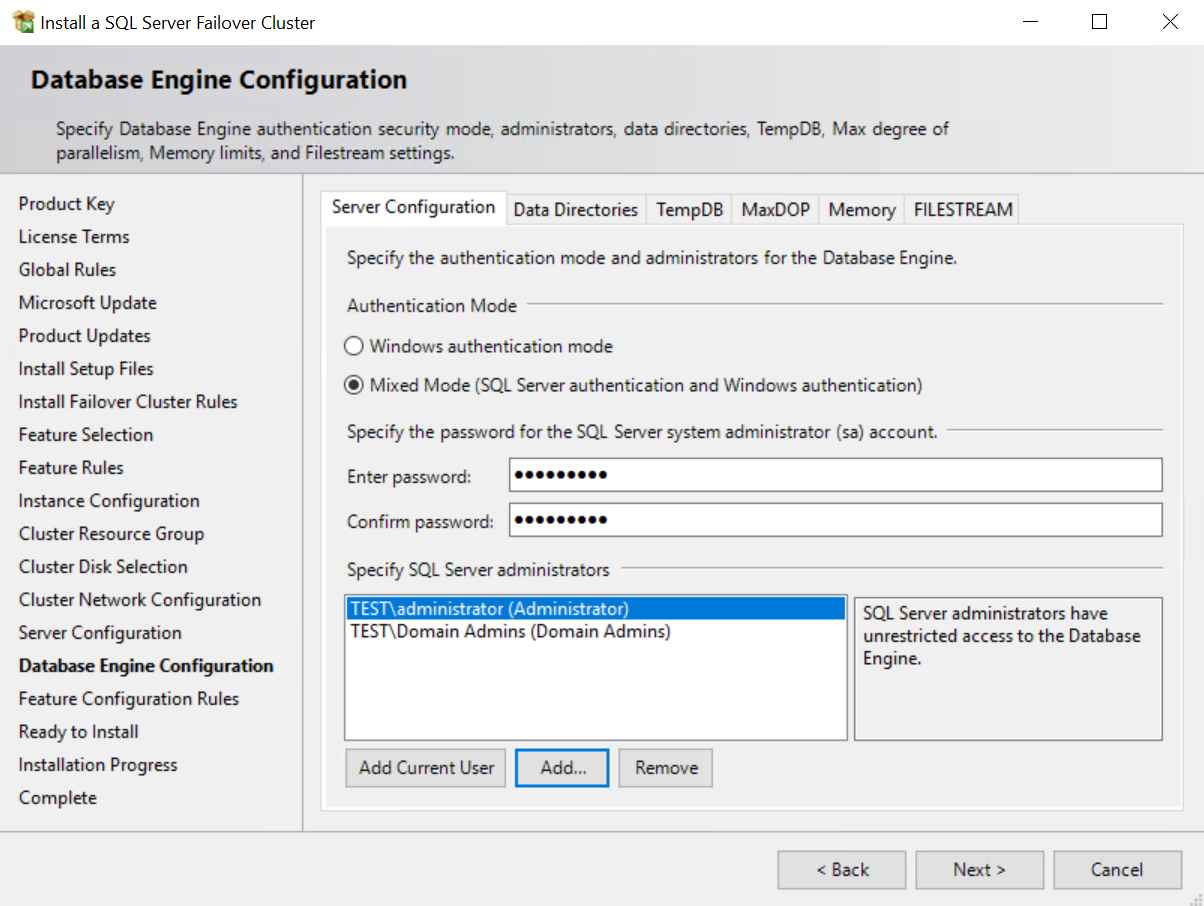 Schritt 7: Serverkonfiguration festlegen |
 Schritt 8: Datenbankpfade auf Cluster Disk legen |
 Schritt 9: Logpfad und TempDB auf Cluster Disk legen |
 Schritt 10: Maximalen RAM Wert festlegen. Ca 90% des verfügbaren Arbeitsspeichers |
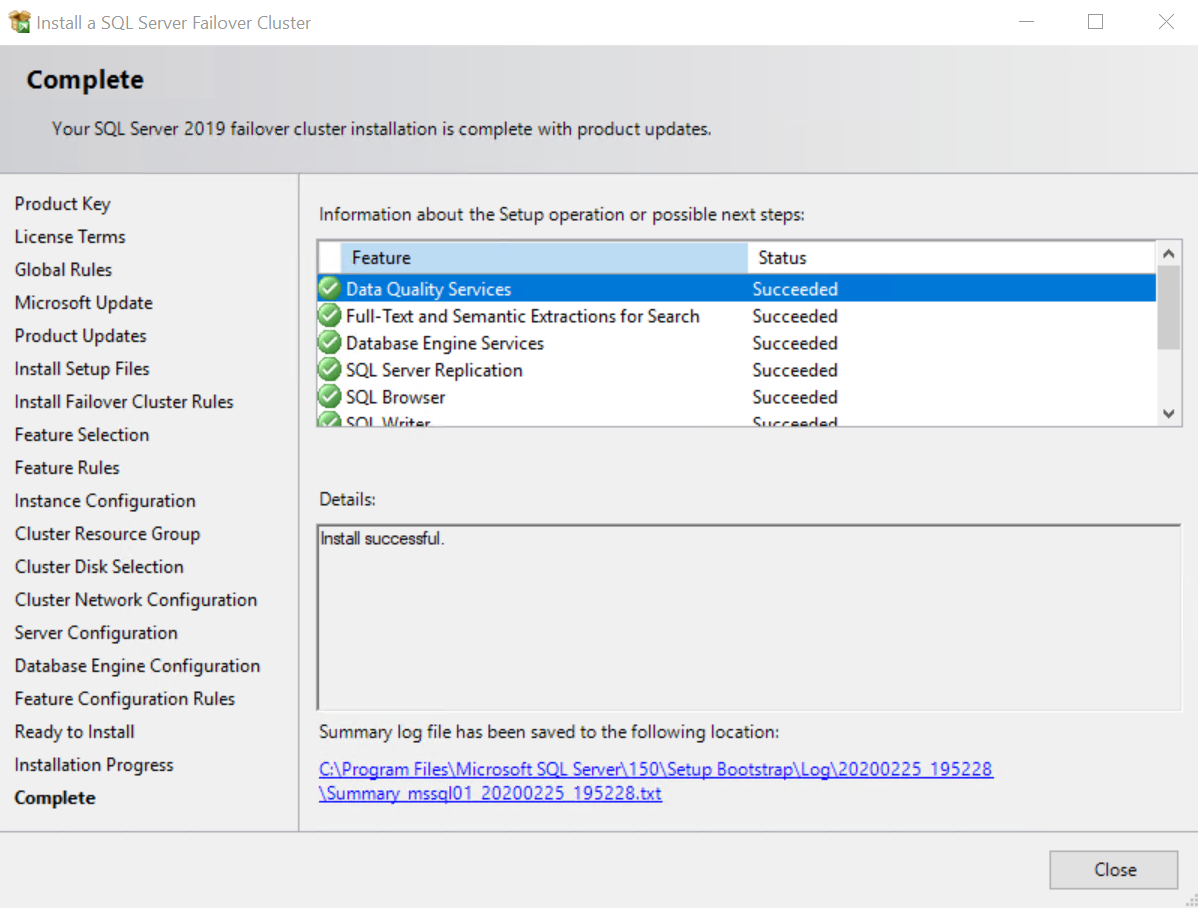 Schritt 11: Die Installation wurde erfolgreich abgeschlossen |
 Schritt 12: MSSQL Cluster ist bereits online |
Somit ist ein Node bereits online und in gewisser Maßen betriebsfähig. Was man an dieser Stelle allerdings noch nicht vergessen sollte, ist unter anderem das aktuellste CU einzuspielen, sowie das MSSQL Management Studio zu installieren. Das Hinzufügen des zweiten Knoten ist eigentlich nur noch Formsache und wird daher nur kurz angerissen.
 Schritt 1: Add node to a SQL Server failover cluster |
 Schritt 2: Bestehenden Cluster auswählen |
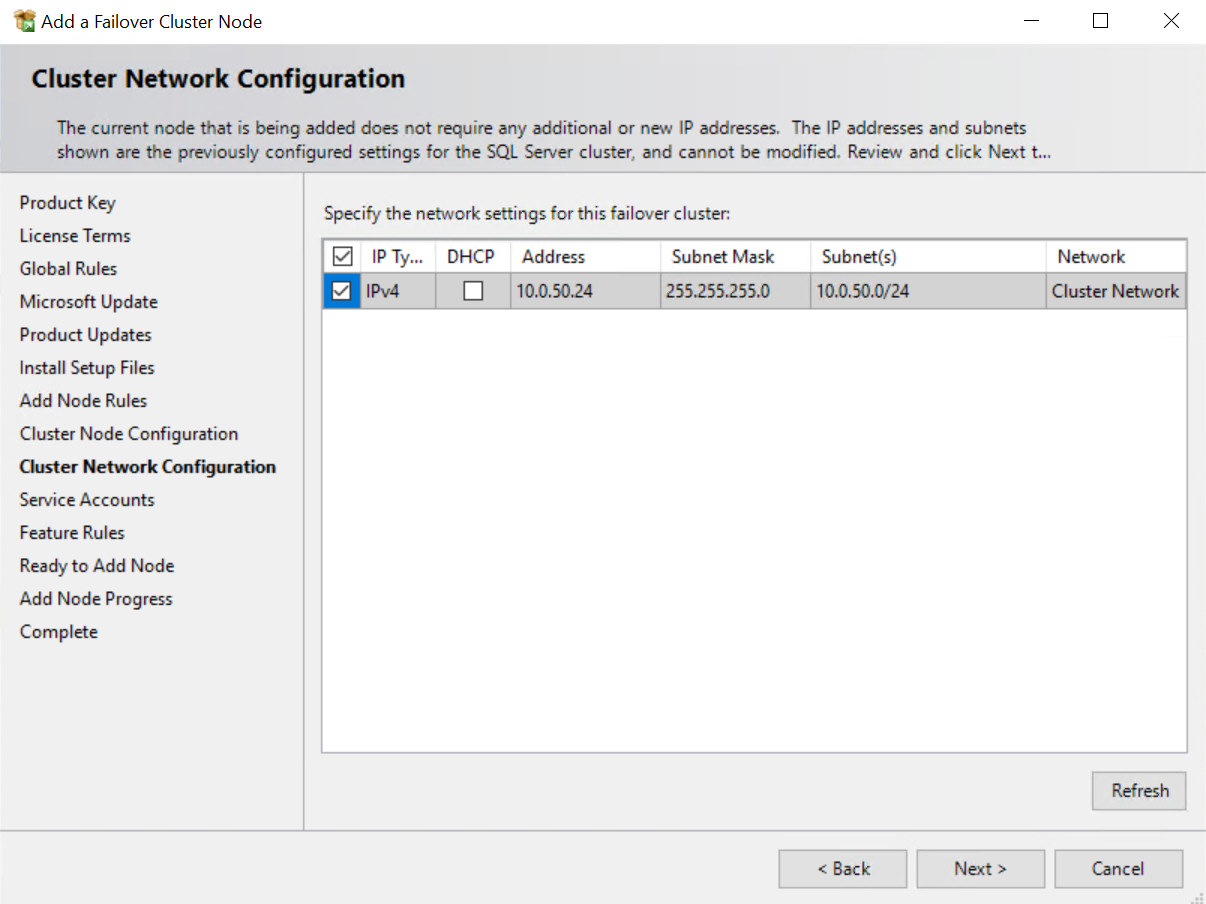 Schritt 3: Cluster Network auswählen |
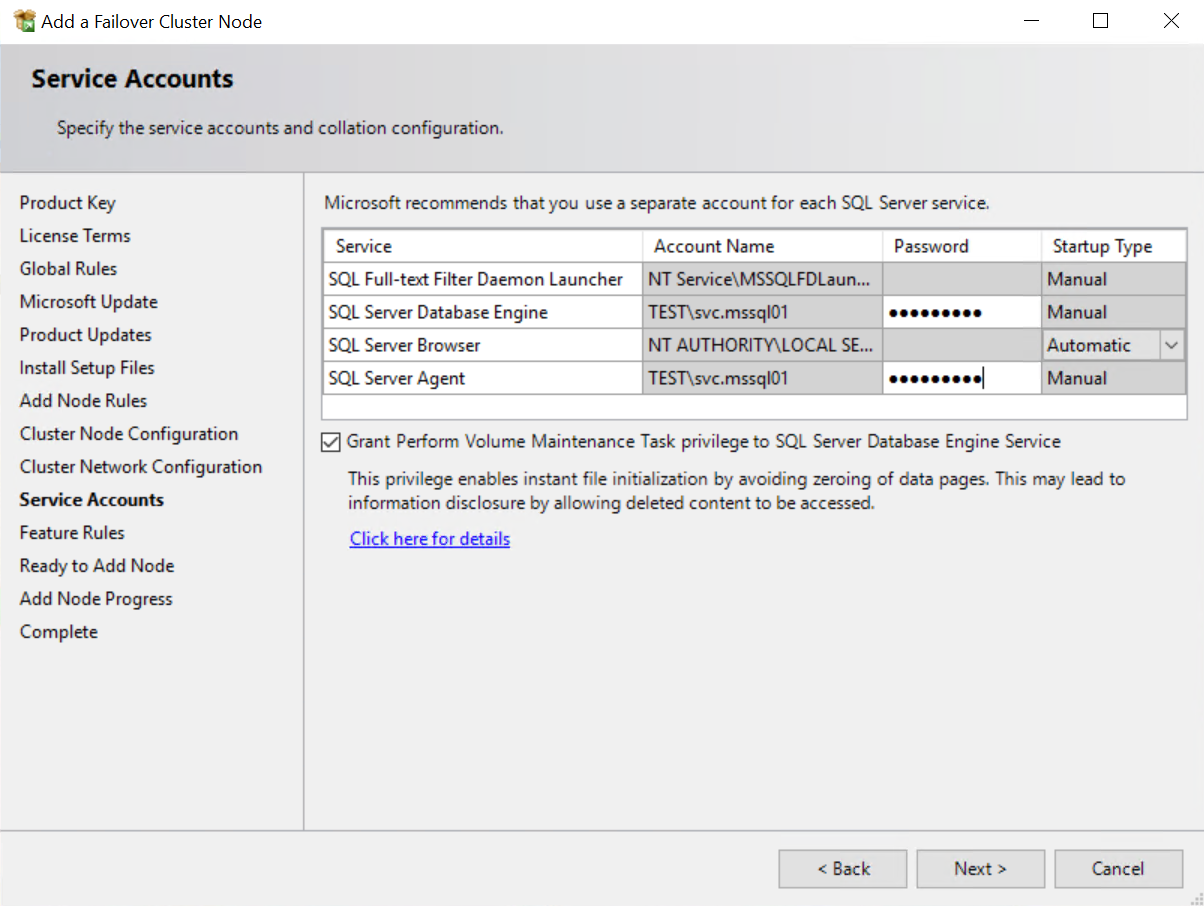 Schritt 4: Service User Passwort eingeben |
Abschließende Tests
Abschließend darf natürlich das Schlussplädoyer nicht fehlen: Testen, testen, testen! Wie verhält sich der Cluster in eurer Umgebung. Bereits kleinere Tasks, die eigentlich im Hintergrund laufen, können einen Clusterschwenk initiieren. Bestes Beispiel: Veeam erstellt einen Snapshot der VM um das Backup auszuführen. Dauert das Erstellen des Snapshots zu lange und ist die VM zu lange eingefroren, wird der Node als offline erachtet und die Dienste werden auf den passiven Node verschoben. Der Hintergrund liegt darin, dass die Teilnehmer unter einander ständig mit sogenannten Heartbeats in Kommunikation stehen. Gehen zu viele Heartbeats hinter einander verloren, wird ein Problem festgestellt und der Prozess geriet ins Rollen. Ein wirklich interessanter und lehrreicher Artikel zu diesem Thema wäre folgender „Tuning Failover Cluster Network Thresholds„.

